
|
|
posted: June 9, 2018
tl;dr: Python and graph databases beautifully hide the complexities of pointers while delivering their power and benefits...
Two of the key technologies that we use in the back end of Uprising Technology’s platform are the Python programming language and a graph database. There is no direct relationship between these two technologies, although there is, of course, a Python driver for the graph database we use, which happens to be mostly implemented in Java. Yet one common aspect of both Python and graph databases that has impressed me tremendously is how each technology uses pointers extensively while completely hiding the implementation details of pointers from code-writing developers.
Pointers are an incredibly useful data structure in computer science. At its bare essence a pointer is a location in memory that contains the address of another location in memory where something of interest may actually be stored (or perhaps it is another pointer). To non-computer folks this may seem silly: you have to store the thing of interest in memory regardless, so why bother having another memory location which contains the memory address of the thing of interest, as you’ll just have to lookup that address to get to the thing of interest? But pointers make computers much faster and make modern high-level programming languages and all the software written in them possible. Without pointers computers would spend the vast majority of their time copying things from one memory location to another, and software would be a lot less modular. Pointers are so fundamental to computer science that computer hardware down at the chip level is optimized for following and manipulating pointers.
Pointers are powerful yet fraught with difficulties in implementation. The C programming language has explicit pointers, and pointer operations are a core part of the language. Successfully using them is critically important, and it isn’t easy. One mistake in pointer arithmetic, or a single occurrence of confusing a pointer with the actual thing of interest, and a C program will likely crash, sometimes bringing down the operating system or computer with it. Pointers are one of those hurdles in early-stage computer science education that some students never get over, quitting in disgust (recursion is another). Over the course of my career I’ve spent countless hours chasing system-level problems caused by some piece of code with an error manipulating pointers.
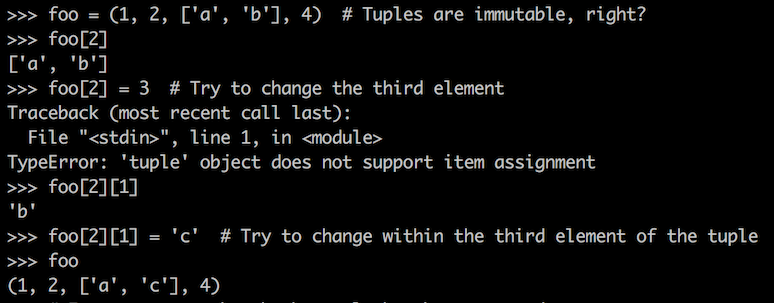
One explanation for this apparent Python anomaly: the tuple stores a pointer to the list, not a copy of the list
Python doesn’t have explicit pointers, but you can tell that they are just beneath the surface in many areas of the language. Lists and tuples aren’t contiguous blocks of memory containing all their elements in sequential order; they use pointers to retrieve, as needed, other objects scattered around memory. Python is a fully object-oriented language, and uses pointers to instantiate objects from classes, invoke methods, and pass objects by reference. Python is also a functional language in the sense that functions are first class objects and can be passed around; what is being passed is a pointer to the function.
Pointers are foundational to many aspects of Python’s high-level programming model, yet Python programmers don’t ever have to explicitly manipulate pointers. Python’s authors appear to have been careful to avoid even mentioning the term “pointer”, preferring to use “reference” in the Python documentation. But because pointers are just beneath the surface of Python, an understanding of pointers and how data is actually stored in memory can help explain what some think of as Python’s quirks, such as the apparent tuple mutation above. I’ve programmed in many languages over the years, including some that required explicit pointer manipulation, and I'm amazed at the way Python's authors used pointers extensively within the Python run-time without requiring programmers to have to worry about pointers.
Pointers are also just beneath the surface of a graph database. Graph databases have two fundamental components: nodes and edges (also called relationships). A relationship is fundamentally a pointer which is stored in one node and which points to the location of the related node. Pointers make it very fast for the graph database to return query results that match patterns of related nodes: as soon as one node is identified which matches the pattern, the related nodes can be easily obtained by following the pointers. Graph databases use pointers to avoid the complexities of traditional table-oriented relational databases, where the relationships are created by generating keys and joining tables together. Graph databases use pointers extensively but they are abstracted away through the concept of a relationship.
A graph database of significant size can contain billions of relationships and hence billions of pointers. Properly managing that many pointers, and not messing up any of them, is a serious challenge. Graph databases take on that chore themselves, so that developers writing code which uses a graph database don’t have to worry about explicitly managing pointers or doing pointer arithmetic. As with Python, the pointers are abstracted away, but they are still there behind the scenes, delivering all the power and benefits of pointers without the complexities.