
|
|
originally posted elsewhere: July, 2018
Behind the scenes of the Uprising Platform is a graph database.
What is a graph database?
There are two fundamental building blocks in a graph database: nodes and relationships. Nodes contain information about something. For example: if that something is a person, the node might contain the person’s first name, last name, and date of birth. There will likely be many of these person nodes in the graph database, representing many different people.
A node in a graph database roughly corresponds to a record or a row in a table-oriented database technology such as a SQL database. Nodes are more powerful than rows because the information in a node is stored in a hierarchical object structure, not a predefined flat set of fields or columns. This means a person node can contain as many email addresses for a particular person as actually exist; there is no need for a separate table to store the person’s multiple email addresses. Additionally, nodes of the same type in the graph, such as the person nodes, do not all have to have the same information fields in them. Nodes are very flexible and easy to change in the future. If it is desirable to add a new piece of information to a person node, such as “favorite_ice_cream_flavor”, that field can put onto the next person node written to the graph database without having to adjust all the existing person nodes.
Nodes are a flexible way to store data, but what really gives the graph database its power is the second fundamental building block: relationships. A relationship is a connection or link between any two nodes. (Note: sometimes the relationships in a graph database are called “edges”, especially in computer science literature.) At any point in time, if there is a reason to link two nodes together, a relationship can be created between those two nodes. For example: one node might represent a person, and a second node might represent a Facebook user. If it is learned that the Facebook user and the person are the same individual, a relationship can be created between those two nodes in the graph database. Once the relationship is created, it can be used to quickly retrieve all the information about that individual: not only the information in the person node, but also the information in the linked Facebook user node.
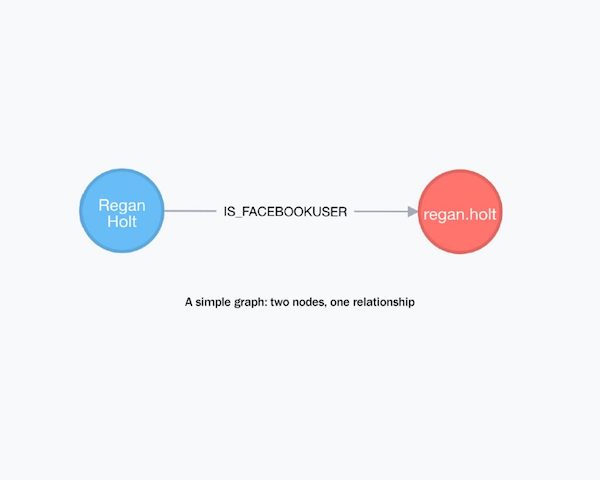
Visually, nodes are typically represented as circles, and relationships as arrows connecting two circles. In the example above the blue circle is a node representing a person: Uprising CEO Regan Holt. Regan’s person node is actually a hierarchical data object containing information about her, such as street addresses, phone numbers, and email addresses. The red circle is a node representing a Facebook user account; that node is a data object containing information about that Facebook account, such as the Facebook URL, display name, and a profile picture. Because that Facebook account is known to be Regan’s, there is a relationship labeled “IS_FACEBOOKUSER” between the two nodes which connects them together. The relationship makes it easy and fast to retrieve Regan’s Facebook account info along with the data stored in her person node.
Data is retrieved from a graph database by pattern matching: a query is submitted to the graph database which describes a particular pattern, and the database retrieves everything that matches that pattern. Graph databases are optimized to pattern match quickly, and are especially fast at following the relationships between nodes. For example, to find all the persons who are known to have a Facebook account, the graph database would be queried to return all the person nodes which have a relationship (i.e. are connected to) to a Facebook user node. To specify patterns in the query, a graph database will typically have its own query language which is not SQL; hence graph databases are one type of “NoSQL” database.
How Uprising uses the graph
The graph database used in the Uprising Platform is the primary persistent data store. The Uprising Platform loads data from a variety of sources: client databases, social media services such as Facebook and Twitter, third-party data vendors, and the Internet in general. There are a variety of automated data load jobs which run at different points in time over the course of the day to bring new data into the Uprising Platform. When that data comes into the Uprising Platform, individual records are transformed into Uprising’s internal object-oriented data format, then they are stored as nodes in the graph. If a node already exists, it will be updated. For example, the regular daily job which loads data from an Uprising client’s database might be given a record which contains an updated phone number for a person; that person’s node in the Uprising graph database will then be updated with the new phone number.
After nodes are written, relationships are then made (or updated) to other nodes in the graph where a relationship is known or thought to exist. Some relationships are explicitly known and are determined by client data: the client database may say that a particular person is a member of a particular group, such as an alumni organization. In that case a relationship will be placed in the Uprising graph database between the node representing that person and the node representing that group.
The more interesting case for building relationships occurs across different types of data load jobs, such as the social media service and third party data load jobs. Each data load job writes to specific nodes and relationships in the graph database associated with that source of data. For example, Uprising’s job which pulls in Facebook data writes to Facebook user nodes, and Facebook post nodes, etc. But when a relationship can be established between a Facebook user node and a person node in the client’s data, a relationship is created in the graph and then all the Facebook data for that person can be easily referenced and presented to Uprising users in the front end.
This relationship between a Facebook user and a client’s person record can be established at any point in time, and via a variety of methods: from the client’s data itself, from an Uprising user confirming a social media account for a person, or from the Uprising Identity Resolver. The relationship can also change over time: it can start out as a “suggested” relationship or match, and can become more certain after being confirmed by an Uprising user.
The Uprising Identity Resolver is the subsystem which matches the identity of a person in one set of data with the identity of that person in another set of data. The matching criteria are, necessarily, data dependent and vary across different sources of data. The matching results from the Uprising Identity Resolver also can vary, depending on how strong a match and how many matches are found across the multiple data sets. When a match is found, an appropriate relationship between two nodes in the Uprising graph database is created. Once created, all the data that is associated with that person in the graph database is available to be displayed to Uprising users.
The final step is getting the data out of the graph database and presenting it to Uprising users via the Uprising front end. The Uprising front end is a responsive web application running in the user’s browser. To communicate with the Uprising database it uses a secure internal Application Programming Interface (API) and sends queries to that API to ask for the information the user has requested. Some of the information can be directly returned from the Uprising graph database; other queries are handled by the Uprising search engine, which provides keyword search functionality, synonyms, and other rich search features. Behind the scenes the Uprising search engine gets its data from the Uprising graph database and prepares documents to be returned in response to queries. The ultimate source of the data is the Uprising graph database.
The benefits of the graph
Uprising’s use of a graph database delivers some important benefits to users of the Uprising Platform:
As new data flows into the Uprising graph database, it is immediately linked up to the existing data in the graph via relationships. If an identity relationship exists connecting a person node to that new data, the new data is immediately viewable in the Uprising front end. If a new identity relationship is created to connect a new person to existing data, that existing data is immediately associated with that new person. In other systems that use table-oriented databases, there often is a need for large batch jobs that are run to search across multiple tables and build up new tables of relationships. These batch jobs don’t run continually, which creates a lag between when the data is loaded and when it is fully visible to a user.
In the Uprising platform, when a Twitter user sends out a Tweet containing a keyword (such as a hashtag) being monitored by Uprising’s Twitter miner, that Tweet and the Twitter user who sent it are loaded into the Uprising graph. If that Twitter user is already known to be a certain person in an Uprising client’s database, then that Tweet is immediately connected up via relationships to that person. An Uprising user can then immediately see that Tweet and the fact that it was sent by someone from their database.
Table-oriented databases and graph databases can both store terabytes of data. But graph databases tend to scale better for handling more different types of data, and for connecting it all together in a quick and easy way. This means that the Uprising graph database can more easily grow in the future to bring in data from more and more sources, connecting it all together, and presenting it to Uprising users in order to provide a richer set of information about people. Traditional table-based databases can store lots of rows and columns, but they tend to reach their limits when the number of tables that must be joined together to provide a complete view of information reaches the limits of human (programmer) comprehension.
Compared to table-oriented databases, a graph database eliminates most database refactorings and migrations. This speeds up Uprising’s development cycle and gets new features into the hands of Uprising clients faster. The object-oriented nature of the nodes in a graph database makes it easy to add new fields of information: the new field is just added to the next node written to the graph database. New types of nodes can be created just by writing the first instance of that new node to the graph database. Any two nodes can be connected via a relationship simply by writing that relationship between those nodes in the graph database.
Traditional table-oriented databases have several decades of development and performance optimization behind them, and are plenty fast for most applications. But in head-to-head performance tests, graph databases are often faster for retrieving data across multiple related nodes. In computer science terms the relationship is a “pointer” that points to the location of the node at the other end of the relationship. Computers are highly optimized for following pointers, meaning it is very fast to traverse the graph and find connected data. This can improve the speed at which the Uprising database is able to retrieve information to be presented to the user, resulting in a quicker response time to queries.
Conclusion
Table-oriented databases are commonly called “relational” databases, but graph databases take the concept of a relational database to a whole new level. In a graph database the relationship is explicit and is one of the two fundamental elements of the database, along with nodes. A graph database is optimized for ease and speed of creating relationships and for finding data connected by relationships.
Uprising’s use of a graph database delivers a rich set of information and features to Uprising users by connecting data from a variety of sources. All the information that can be identified as being associated with a person is linked to that person via relationships in the graph database. Over time, as more data from more sources is brought into the graph and connected up to existing data, the richness of the data that Uprising presents to the user will continue to grow.