
|
|
posted: August 29, 2020
tl;dr: Avoiding “garbage in, garbage out” is actually harder than you might think...
It’s the fall of 1982, and I’m taking CS211 at Cornell as a first-semester freshman. I forget some of the details of the first assignment, but it involved prompting the user to input some data and then running that data through an algorithm that would yield the desired result. I wrote my PL/C program, tested it with a variety of input data, and turned it in, confident that I had come up with a solution that worked.
When I got the graded assignment back, I was surprised to see that points had been deducted. I knew my code worked. But I had not done any bounds checking on the data input by the user, to ensure that it was within the range of valid inputs for the algorithm. If the user entered a nonsensical value, my code could blow up. Since I can’t remember the details 38 years later, I can’t recall the exact problem. It might have been an index out-of-range problem, or a divide-by-zero problem, or just a computation that resulted in an obviously wrong answer. I was a bit miffed, because there appeared to be an implied assumption in the assignment that the user would input valid data. But I had not enforced that, and hence points were deducted.
I learned my lesson. From that point forward in both my collegiate and professional career, I have tried to implement validity checks whenever user data came into my code. This is easier said than done, however, which is why the software industry still suffers, decades later, from problems triggered by unexpected user input data. These problems can be as nefarious as the SQL injection attack described in the XKCD comic strip below, or a Cross Site Scripting (XSS) attack. Or they can be more minor, such as strange program behavior when the user enters certain data.
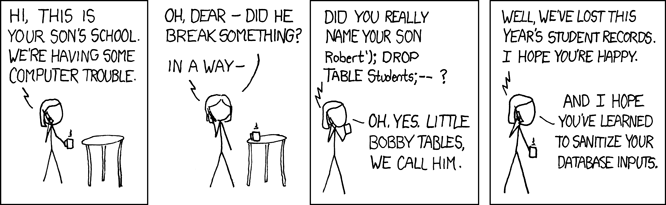
The CS211 assignment where I had neglected to validate user input was trivially simple in comparison to most modern day applications. All the code was written by one person: me. I was fully aware that a user was going to enter some data into the program, since I wrote the code that prompted the user. I also wrote the algorithm that used the user’s data, so I was fully aware of what was and was not valid input. I also knew the types of errors that faulty data could cause. Once I was aware of the need, I could easily write some code to create a perfect filter that would pass all valid input data and block all invalid data.
Most real-world applications are much more complex, involving multiple layers of software and different teams of programmers, who may not work for the same company. Let’s say Company A is developing a web application that accepts user data from form submissions. When a form is submitted, the webapp invokes a third-party service to send an email by calling Company B’s RESTful API with some of the user-entered data from the form. Company B happens to store some of that data in an internal SQL database, and has written the queries to that SQL database in such a way that they are vulnerable to a SQL injection attack. I prefer to solve problems closest to the source, which means Company B’s code in this example, but that’s not always possible to do.
Company A has no idea that Company B is even using a SQL database, as its contract with Company B is the API spec. Company B could even swap out that SQL database for some other NoSQL database technology in the future, and it shouldn’t affect Company A. But because the entire system is vulnerable to a SQL injection attack and Company A (not B) is delivering the webapp to the customer, Company A may need to cleanse the user data of character sequences that could be part of a SQL injection attack. Company A also may have to cleanse user data of character sequences that could be part of an XSS attack. It’s hard to come up with a perfect filter, and any filter may prevent the user from entering character sequences that Company A actually wants the application to be able to accept.
In larger systems, there may be even more independent layers. As independent layers, each layer might have to safeguard against possible problems in the layers above or below. The end result can be that the validation of user data happens multiple times in multiple places, negatively impacting the system’s efficiency and latency. Fortunately there are many tools available to enforce schemas and to validate data, and custom code can always be written.
Even though it was made painfully clear to me decades ago that there is a need to cleanse user input data, it remains a challenge for the industry as a whole.