
|
|
posted: December 18, 2020
tl;dr: How to maximize your chances of seeing the latest-and-greatest content on the Web...
Have you ever browsed to a website and realized that you are looking at an old version of the site? Maybe you’ve been told that the site has just been updated, but when you browse to where the updated content is supposed to be, you see old content. There are technical reasons for that situation, as well as ways to detect when it is occurring. Even better, there are ways to potentially resolve the situation.
Broadly speaking there are two types of content (or data or information) on a webpage: dynamic and static. Dynamic content changes rapidly: what you see on the page one moment may differ from what you see the next moment. Examples include a page showing the current outdoor temperature or the price of a stock, the checkout page on an ecommerce site, and a Web-based email tool such as Google Mail (Gmail). As the temperature or stock price changes, or as you add or delete items from your ecommerce order, or as you receive and interact with emails, the content on those pages changes. Ideally this happens in as close to real-time as possible.
Static content, you might think, doesn’t change. That’s not entirely true, however. A better way to think of it is that static content doesn’t change very often. This blog post and nearly my entire website are static; yet occasionally I do update existing pages. After doing a post, I might fix a typo or add a link. When I do so, I’ll deploy the updated static page to AWS, which currently hosts this website. But it may take a while for all users to see the updated content; that is the problem I’m focusing on in this post.
Webpages can contain a mix of static and dynamic content. A good example is the Gmail inbox page. The contents of the inbox are dynamic, and can change without any user interaction as new emails are received. But in the upper lefthand corner of the page is some static content: the Gmail logo. The Gmail logo doesn’t change often, but Google did just recently change it. After Google made the change, some users quickly saw the new logo, while others did not.

The fundamental reason for this is that, in the modern Web, static content is often cached in various locations in between the browser page being displayed on the user’s device and the original source-of-truth for the content (called the “origin”). Somewhere in the world there is a single server that functions as the origin for the Gmail logo. However if every Gmail user in the world accessed that one server every time they went to their Gmail inbox page to retrieve the latest version of the Gmail logo, that server would be overwhelmed with requests. So static content is typically cached.
A cache, on the Web, is nothing more than a server that stores copies of content. The caches get their content from the origin, or from other caches closer to the origin than they are. There can be thousands of caches that each contain a copy of the Gmail logo, with users in geographic areas directed to a nearby cache to retrieve the content. This not only helps reduce the load on the origin, but also reduces overall network traffic within the Internet. Some static content, such as videos, music, and large images, can be quite large in size. If your browser goes to a cache in your city to get a video file, that reduces the amount of Internet traffic that needs to traverse the Internet all the way to the origin, which in the case of Gmail might be Google HQ in Silicon Valley. Caching static content is the primary function of a type of network known as a “Content Distribution Network” (CDN). Popular CDNs include Akamai, CacheFly, CloudFlare, Google Cloud CDN, Rackspace, and the one that I am currently using and which sent you this static page, Amazon CloudFront.
The items in a cache will each have a “refresh interval” or “time to live” associated with them. That value determines how long the cache will store a recently obtained copy of the item before going back towards the origin to check if there is a newer version available. If that value were zero, and the cache always checked with the origin to see if there was a more recent version available, it would defeat some of the purpose of having a cache. So the normal behavior of a cache is to respond to a request with the copy of the content that it has, and to occasionally check to see if a newer version exists.
The caches within a CDN are typically within control of the website owner. When a website is updated, and new content exists at the origin, the website owner can force a refresh of all the caches within the CDN. This forces the CDN caches to go back to the origin to obtain a copy of the most up-to-date content. The next time a request comes into a CDN cache for content, the CDN cache will respond with that refreshed content.
CDN caches are not the only caches in between the user’s browser and the origin. Internet Service Providers (ISPs) may cache content, to reduce the bandwidth demands on their network. ISP caches are within the control of the ISP, so there is nothing that either a user or the website owner can do to force a cache refresh. There is, however, one more very important cache that is often the culprit for a user not being able to see the most up-to-date static content on a website: the user’s browser cache.
Browsers also cache static content, in memory and/or disk. This can dramatically improve page loading time when the user revisits a page that was recently viewed, as the browser doesn’t even bother going out to the Internet to retrieve static content that it obtained recently. If you are comfortable using your browser’s developer tools, you can see this happening. Here’s a view of the network activity in my Google Chrome browser showing how it obtained the Gmail logo when I browsed to my Gmail inbox page: it got the logo “from memory cache”:
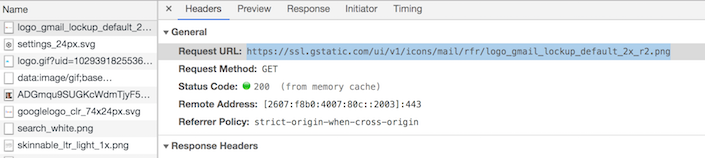
Here’s another view. This time my browser obtained the Gmail logo from IP address 172.217.164.99. Running a “whois 172.217.164.99” command tells me that that IP address is from a block of IP addresses owned by Google, probably within their own CDN. So I can be reasonably confident that my browser obtained the Gmail logo from Google, and that I therefore have the most up-to-date version of it:
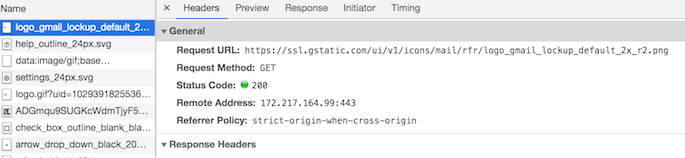
What did I do in between these two attempts? I refreshed my browser’s cache. On Chrome MacOS, this is Chrome -> Clear browsing data, then check “Cached images and files” and click the “Clear data” button. The popup window warns that “Some sites may load more slowly on your next visit”. This is because the browser will be forced to go out to the Internet to obtain all the content. That warning speaks to the entire purpose of caching content in the modern Web.
You can’t control CDN caches; it is up to the website owner to refresh those. You can’t control ISP caches. You can, however, control your browser’s cache. Clear your cache to give yourself the best chance of seeing the most up-to-date static content on a website.