
|
|
posted: March 28, 2021
tl;dr: Software developers love UUIDs, but there is often a challenge convincing users...
In table-oriented databases, such as SQL relational databases, it has been a standard practice for decades to give each new record (row) in the table a unique identifier (ID) which is a sequential integer that is one higher than the ID of the next newest record. The ID of the very first record/row in the table might start at some value greater than 0 or 1. A typical strategy is to plan ahead and anticipate how many records the table may ultimately contain, and make the first ID a “1” followed by enough “0”s so that, over the lifetime of the table, the number of digits in the ID never has to be increased. The ID can be stored as an integer, or perhaps as a string, possibly with a prefix.
For people who appreciate order, myself included, this methodology has some soothing properties. When the table is viewed, from the oldest record at the top to the newest record at the bottom, the IDs will be in sequential order, as ID order matches chronological order. Any gap in the sequence of IDs likely indicates that a record or records were deleted from the table at some point in the past. When two records are viewed elsewhere, perhaps in the application that uses the database table, it can instantly be determined which record is older by comparing the ID values. The very first record in the table is forever recognizable as the oldest record. Because of these properties, and because sequential IDs have been a standard practice for decades, many users expect, and sometimes insist, that IDs be assigned in this manner.
The downsides of sequential IDs are not necessarily visible to users. The downsides are in the realm of the implementation of the database and the application, meaning that the software developers are the primary folks cognizant of them. This sets up a conflict between the users of the system and the implementers of the system, who often prefer a different ID methodology described below.
There are two primary downsides of sequential IDs. First, they create a bottleneck and single point of failure in the system, as IDs can only be generated in one place. In a large scale system with many users, new records can be created by many different users on many different clients, which will be sent into the database to be added to the table. With sequential IDs, there needs to be an ordering mechanism (some sort of queue) that can accept these new record requests and process them in order. That sequential process involves reading the current oldest record, incrementing the ID value by one, and storing the new record with that ID value. This entire operation needs to be “atomic”: if the act of writing the record to the table fails, the ID value can’t be incremented, as it will need to be used by the next record in the queue, to prevent a gap in ID values. In very large systems, this can create performance issues.
The second downside affects both large and small scale systems: the client code that generated the record can’t know the record’s ID until after it has been successfully written to the database. The client needs to send the new record to the database, wait for the ID to be assigned, and hope that it is successfully returned, before it can act upon the ID, such as displaying it to the user or storing it locally. If the communication between the client and the database is interrupted before the ID is returned to the client, the user won’t know the ID that was assigned, which can make it more challenging to look up the record later.
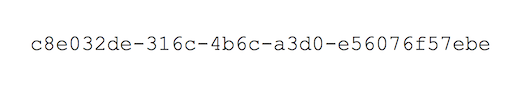
A UUID is much cheaper and easier to generate than a Bitcoin
What if there were a way for the many clients of a system to tell the database what ID to use for each record, instead of the database telling the clients what ID it assigned to each record? That is the problem that Universally Unique Identifiers (UUIDs) solve.
UUIDs are effectively extremely large random numbers, represented as a string of digits, characters, and dashes to make them more readable. The number of possible UUIDs is so large that the odds of two independent systems generating the same UUID are infinitesimally small: they can be thought of as unique. UUIDs are cheap and easy to generate. Many programming languages can generate them by using a standard library function.
By using UUIDs, the ID for a record can be generated by each client at the point where each new record itself is being generated. The record’s ID is immediately known, and can be shown to the user and stored locally. Showing the UUID to the user, however, demonstrates one of the main drawbacks of UUIDs: the values are long and unwieldy. Users can react negatively, especially if they think they will have to write down and possibly type the value in the future. In practice, because there are so many possible UUID values, in most systems records can be found by entering a small number of characters at the start of the UUID. After eight or so characters, there is likely just one matching record in the system; the rest of the UUID characters are usually superfluous. It may be possible to shorten the number of characters shown to the user. For records where it is not necessary to show the ID to a human user, this limitation of UUIDs doesn’t matter.
The other downsides of UUIDs, in comparison to sequential IDs, are in the realm of database management. It won’t be possible, by looking at the record IDs, to detect where records may have been deleted, if UUIDs are used as the record IDs. Some other scheme will need to be used, such as logging deleted record IDs. To sort the records in chronological order, it will be necessary to sort them by a timestamp of when the record was originally created or entered into the database. It’s a good practice to timestamp records anyway, even with sequential IDs, so this is not much of a drawback.
Using UUIDs can lead to a more robust, scalable system, and also one that is easier and faster to develop. They are an obvious choice in situations where an ID is needed but it doesn’t need to be shown to a human user. Even in situations where the ID does need to be shown to a user, I am seeing UUIDs become more prevalent.
Related post: Aliases vs. IDs
Related post: Storing database records that lack a unique ID