
|
|
posted: May 22, 2022
tl;dr: These are the aspects of AWS Glue that I like...
I recently used AWS Glue in a couple of projects, both of which involved reading data files from S3 buckets and writing the records in them to an AWS RDS Postgres instance. These projects were a near-perfect fit for the paradigm of Glue, which is AWS’s Extract-Transform-Load (ETL) service/tool. Here are the good aspects of Glue, based on my experience:
A good fit for ongoing ETL jobs on large amounts of data
There are certainly other options for loading data into a database. You could write your own script to read the files, transform the data, and write it to the database. You don’t even need to run a script like this on AWS: the files could be in S3, the database could be in RDS, but your script could run locally. Glue, however, shines when you have large amounts of data: millions of records spread across a large number of files. It especially shines when the data grows with time, and you want to automatically load new data as it shows up.
Glue is wicked fast
Glue automatically scales up your script to run in parallel across multiple servers. It hides all the details of this from you, so you don’t need to do anything special in the script’s code. The results are blazing fast. Writing to a mid-range RDS Postgres instance, I am seeing Glue load 10,000,000 records in under 10 minutes. Perhaps other types of destinations would be even faster, I don’t yet know. It was more than enough performance for my needs.
Can easily reload all the data
If you keep your source files intact and don’t delete them, then you have the ability to re-run an entire load job anytime you want. Just delete the destination table, and re-run the entire job. This can be a boon in case you later notice a problem with the resulting data that requires a tweak to the script to produce better results. Just make the script modification and re-run the entire job and you’re done.
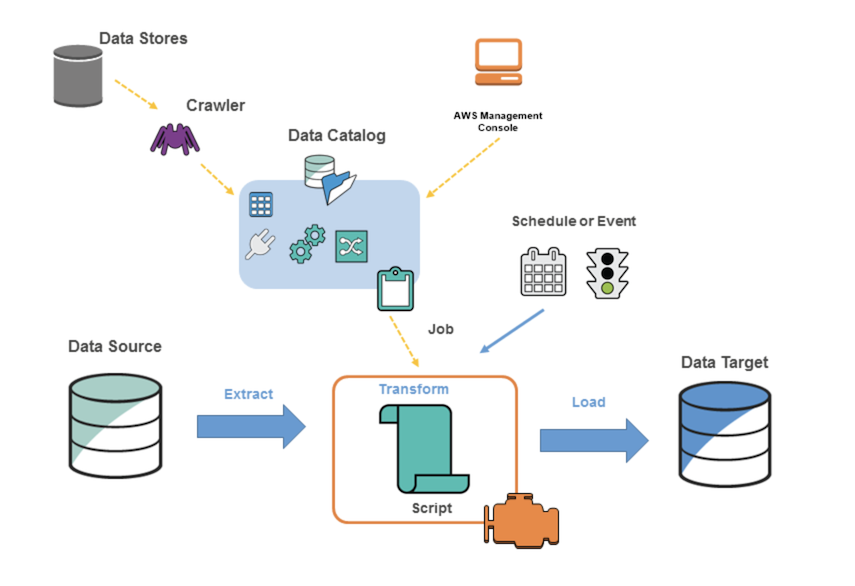
AWS Glue is a good tool that could use a better architectural diagram
Lower development time
Like any tool or programming paradigm, Glue has a learning curve. Once you get through the learning phase and become competent with Glue, it can significantly shorten the development time for new ETL jobs.
Can use Python and its data science libraries
Python is the most popular language for data science. Glue can automatically generate a script which is a starting point for your ETL job, which you can then modify to obtain the desired results. For those programmers who are familiar with Python data science libraries such as pandas, and who are used to operating upon data frames, the Python scripts generated by Glue will look familiar. At the start of the Glue script, you are delivered a dataframe-like object which represents all your source data, which you can then transform as needed. If you need other Python data science libraries, you can import them.
Can turn on automation when ready
You’ll probably start your AWS Glue job by processing some source data that already exists. Once you have the output looking the way you want, and once you are confident that new source data will be delivered in the format that Glue is expecting, you can easily turn on automation so that new source data is processed as it shows up.
Can hook into other AWS services
Glue truly is an ETL tool: it just extracts, transforms, and loads data. If you need to do something beyond the ETL paradigm, then you can utilize other AWS services and invoke them either before or after Glue does its work.
Related post: AWS Glue: the not-so-good stuff
Related post: Software that’s so smart it’s stupid