
|
|
posted: May 28, 2022
tl;dr: These are the aspects of AWS Glue that could use some improvement...
I recently used AWS Glue in a couple of projects, both of which involved reading data files from S3 buckets and writing the records in them to an AWS RDS Postgres instance. These projects were a near-perfect fit for the paradigm of Glue, which is AWS’s Extract-Transform-Load (ETL) service/tool. I’ve already covered the good aspects of Glue, so here are the not-so-good aspects, based on my experience:
Glue only does ETL jobs
Glue strictly adheres to the extract-transform-load paradigm. Data can only be read from the source, and can only be written to the destination. In contrast to ETL is the CRUD paradigm, which specifies the four main operations that are done on records in a database: Create, Read, Update, and Delete. Glue can only Read from the source, and can only Create records in the destination. In particular it cannot Update or Delete records in the destination, since that would involve reading (or extracting) from the destination, as well as doing something other than loading (Creating) records in the destination. When the destination of a Glue job is a database table, a Glue job is append-only: new records that are read from the source will be appended to the database table, which will forever grow in size.
Given that limitation, it may still be possible to use Glue for a job that involves updating records in a destination database table. One of the AWS Glue jobs I wrote was for user profile records. Whenever a user profile was updated, a new entire profile record appeared in the source data. The AWS Glue job wrote all the user profile records to a destination table, so when a new profile record for a user appeared, it would also end up in the table along with the user’s previously-written profile record. I then created a SQL view table that just returned the most recent record, based on timestamp, for every user profile. The actual table had all the profile records ever loaded, but the view table had only one profile record, the most recent, for each user.
The other way to work around Glue’s strict adherence to the ETL paradigm is to utilize other AWS services, such as Lambda, in addition to Glue. It’s possible for Glue to gain additional functionality which would make it useful for more types of tasks, but then it would no longer be strictly an ETL tool.
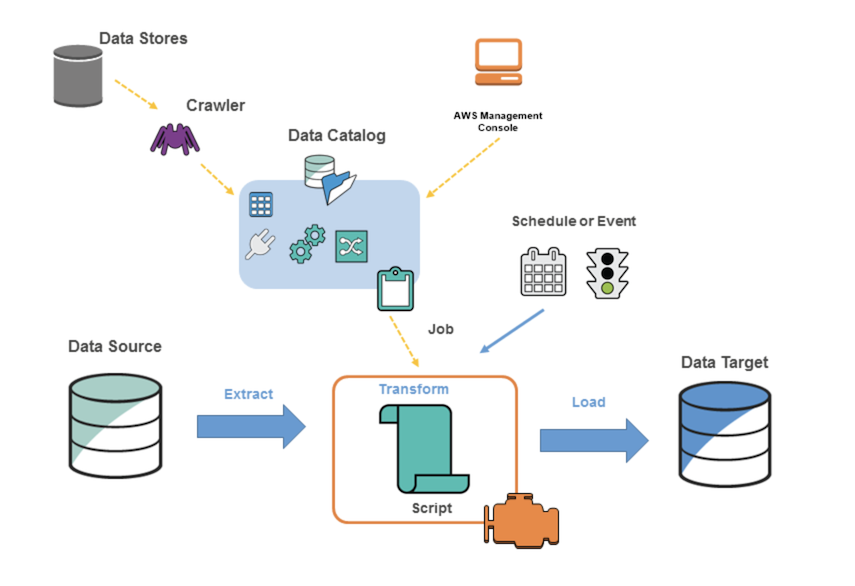
AWS Glue is a good tool that could use a better architectural diagram
Rigidity in its directory structure, file names, and schemas
The AWS Glue crawler, which finds the source data for a job (especially files in an S3 bucket), is not as smart as I was hoping it would be. When different types of source files (say sales records and returns records) are intermingled in the same S3 bucket, if they are not organized into entirely separate directory/folder structures, Glue can have a hard time finding all the records/files of each type. Strangely, Glue uses an exclude filter, in which you can tell it patterns of file names to exclude from a crawler, rather than an include filter. So you have to explicitly tell Glue all the files to exclude from a crawl, rather than telling it just which files to include in a crawl. Since new, never-before-seen types of files may be added to the S3 bucket in the future, an exclude filter requires maintenance, whereas an include filter should require no maintenance, as long as there is some pattern in the filename that forever uniquely identifies the type of data in the file.
The actual data files all need to be located at the same level in the directory hierarchy beneath the directory/folder at which you point the Glue crawler. If a file is ever placed in a location that violates the hierarchy, chaos can result. This shouldn’t be a problem if the files are being deposited in S3 by an automated job, but if humans are placing those files in the S3 bucket, good luck. If files ever appear that violate the schema that Glue deduced from prior files, bad things can also happen. And dometimes, bad things happen because the Glue crawler's algorithms change.
Dealing with the vagaries of user-generated and deposited data files is a challenge that Glue mostly avoids by insisting upon structure. If the data files have lots of issues, it may require writing a job outside of Glue that finds all the files for each Glue job, enforces a schema for each, and places them in a different S3 bucket or directory structure. The Glue crawler can then be triggered after all the files have been properly cleaned up and organized.
Hard to debug a Glue job
Although Glue can generate Python scripts, there is no access to a Python runtime environment when the script runs. The script is farmed out across multiple servers, which gives Glue its speed, but debugging a Glue job is not as easy as adding print statements or firing up the Python debugger. The CloudWatch logs for a Glue job tend to be voluminous, and the error messages that propagate to the Glue console when a job fails are cryptic.
Because of all this, although the Python scripts that Glue generates are pretty straightforward and the code will be familiar to anyone who has used the Python data science stack, Glue jobs require a higher level of Python expertise to debug. It helps to know what types of exceptions Python can throw and when, and how to handle type conversion issues. I used an incremental approach as I always do, starting with the Python script that Glue generates, which should be runnable. I added features and changes in an incremental fashion, and ran my job quite often (the speed of Glue helps with this). When the job failed, I stared at my code and figured out what I may have done to screw up the Glue job, as Glue itself didn’t provide many clues. Sometimes the script would run, but weird (especially NULL) values would appear in the destination table. Experience helps solve these problems quicker.
Not as robust and mature as other AWS services
Glue has some rough edges that, hopefully, AWS can improve upon. A Glue crawler takes a long time to “stop” after it has generated the output table. Although you can edit the crawler while it is stopping, you cannot save your edits until the crawler has fully stopped. It’s not clear what the crawler is doing while it is stopping, other than internal AWS housekeeping. Sometimes crawlers are significantly slower than usual to run. I’ve already mentioned that Glue’s error messages are cryptic. The Python scripts that Glue generates work, but they can generate some lines of code that span 1000 columns, rather than breaking a line into multiple lines. I’m not a strict adherent of the Python PEP-8 standard of 80-column lines, but keeping lines to ~120 columns, so that they better fit into Glue’s own script debugger window, would be nice.
Glue’s documentation is reasonably good, but since Glue is nowhere near as popular as other AWS services such as Lambda, S3, and EC2, you’ll get fewer hits on search engines and StackOverflow when you seek online help for an issue. That should change with time.
Don’t get me wrong: these downsides did not prevent me from having success using AWS Glue. I’m glad I chose it for the projects I did, and I would gladly choose it again.
Related post: AWS Glue: the good stuff
Related post: Software that’s so smart it’s stupid