
|
|
posted: December 24, 2022
tl;dr: Tips and tricks for finding and fixing missing database records...
The fraternal (not identical) twin problem of a database with duplicate records is a database with missing records. Often they are the same database: most large databases have both issues. Both are caused by less-than-perfect processes in getting records into the database. Since we inhabit the real world, not some theoretical perfect world, if you notice one of these problems, you’ll probably also find the other if you look hard enough.
Here is how I deal with finding, and then hopefully repairing, missing database records:
Look for gaps in sequential IDs
This is the trivially easy case. If each record has a unique, sequential ID assigned by some upstream system when the record is created and before it is sent into the database, then all you need to do to find out whether there are missing database records, and how many there are, is to look for gaps in the IDs of the records in the database. A SQL query can be written to do this. In fact, the ease of finding missing database records is the main advantage of using sequential IDs in a data processing system. The downside of sequential IDs is that the centralized process which assigns the IDs may not be easy to implement in a large distributed system, as it represents a scaling bottleneck. There’s also the problem of handling failures that may occur after the ID is created but before the record is fully created and stored someplace. For these reasons, many large distributed systems use non-sequential IDs such as UUIDs.
Look for large gaps in timestamps
If the records’ IDs do not provide any useful information for finding gaps, then a high-resolution timestamp might. This requires some knowledge about the overall system and how the records are produced at the source. The trivially easy case is a data collection system, such as a weather monitoring system, that collects information and creates records once every fixed time period (a second, a minute, an hour, etc.). Then you can look for gaps in the timestamps of the database records that exceed the fixed time period.
In the more general case, you’ll need more knowledge about the overall system. Say the records are produced each time a user makes a purchase on a non-Amazon-scale e-commerce site that serves a domestic audience. A gap in records of an hour or more during the daytime may point to a problem, if the site normally records multiple purchases per hour during business hours. A gap of an hour in the wee hours of the morning may not be an issue, however. You’ll have to apply some business logic to determine how best to find potentially missing records based upon timestamp gaps.
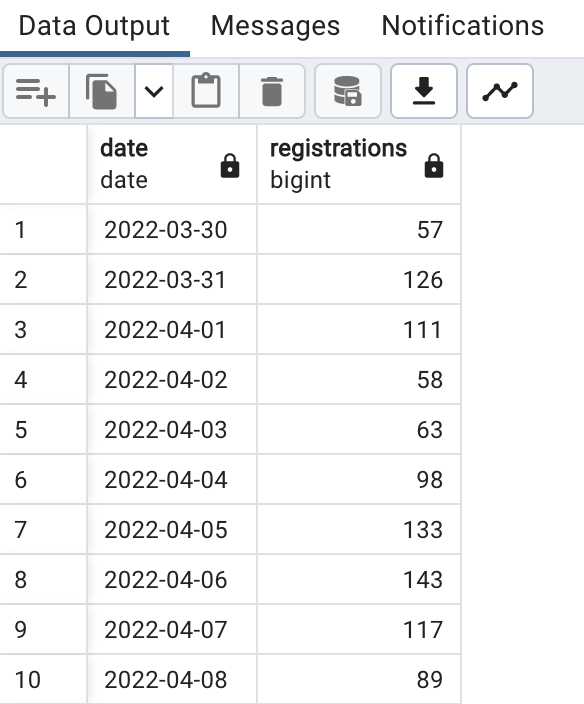
Do these daily counts of registrations make sense, or might there be some missing records?
Count records in fixed time periods
A closely-related method to the prior is to do an aggregation and count the number of records in fixed time periods, such as an hour or a day. You can then do a comparison to either prior time periods or to what is expected based upon business knowledge. If the number of records counted is zero or unusually low, and there is no good explanation based upon real-world behavior, then there may be a problem somewhere in the system.
Automate and notify wherever possible
Whatever method is chosen to detect missing records, it is best to automate it. Manual checking is prone to human error, forgetfulness, vacations, holidays, and staffing issues. Automation can be done by creating a simple job that is run at regular intervals, which queries the database, looks for anomalies including missing records, and notifies a group of people if a potential issue is detected. I like to use AWS Lambda functions for this purpose.
There’s a good argument that whatever monitors a system should be outside the scope of that system. That way it does not rely upon any code in the system, which may have a problem that causes the issue. The monitoring software should be written by someone with overall knowledge of the system, especially the business rules and expected behavior.
Recover missing records from upstream systems
In a data processing system of reasonable complexity, in which upstream systems produce and forward records into a database, it may be possible to recover the missing records. Often upstream systems have their own databases or data storage that stores enough information so that most or all fields within a record, and most or all records, can be recreated and manually inserted into the database. For example, if the records are produced when users fill out a form, there may be a copy of the form submissions stored somewhere upstream of the database.
Often the upstream systems will only store information for a limited amount of time, which is why early notification of missing records can help improve the odds of being able to recover the missing information. Usually some manual investigation is required to determine the best way to recover missing records, so it is hard to fully automate the recovery process. If the missing records resulted from a software issue that can be fixed, then by all means do so in order to improve overall system robustness.
Pay attention to the missing and duplicate information in your database: it can tell you a lot about overall system performance.
Related post: De-duplicating database records
Related post: Look at the data
Related post: Play with the data
Related post: Count the data
Related post: Write the bare minimum amount of SQL