
|
|
posted: July 1, 2023
tl;dr: Sometimes a few lines of deterministic code can outperform the most complex algorithms...
One of the aspects of computers and software that attracted me to the profession is their deterministic nature. With some exceptions, computers and software do exactly what you tell them to do, every single time (note: this is also why they can be frustrating to program, as the programmer is almost certainly the one making the error, not the computer.) If you run a program multiple times, with the same inputs each time, you can expect to get the same results every time. You can’t do that with a human being, for better or worse. This is why computers are so good at automation: once they are able to handle every possible input value and deterministically produce the desired result, they should continue to run forever, or until some part of the system breaks.
When deterministic behavior is desired and expected, and the software does not behave in a deterministic manner, chaos can result. I spent a good amount of time this week dealing with this type of situation in Amazon Web Services (AWS) Glue, an Extract-Transform-Load service that reads data from one location, transforms it, and writes it to another location. Apparently AWS has recently changed the Glue crawler, the software program which finds new data to feed into the next Glue job to get transformed and written to the destination. The changes broke some Glue data pipelines that had been running successfully every day for nearly a year.
I’ve already described the quirky nature of the Glue crawler in my AWS Glue: the not-so-good stuff post. I had long ago organized the input data files into a rigid directory structure, in which every day one new data file would appear in a predetermined location based upon the date. The filename was predetermined and followed a simple pattern. The column names in the file never varied. Because of this, you could give me any date in the future and I would be able to tell you where that day’s file would appear, what its filename would be, and what its column names (headers) would be. All each Glue crawler has to do, once a day, is wake up, find that day’s file, and tell the corresponding Glue job about it. It doesn’t actually have to do any sort of crawl at all, as the file will always be in a predetermined location. I tried to make it as simple as possible for each crawler to succeed.
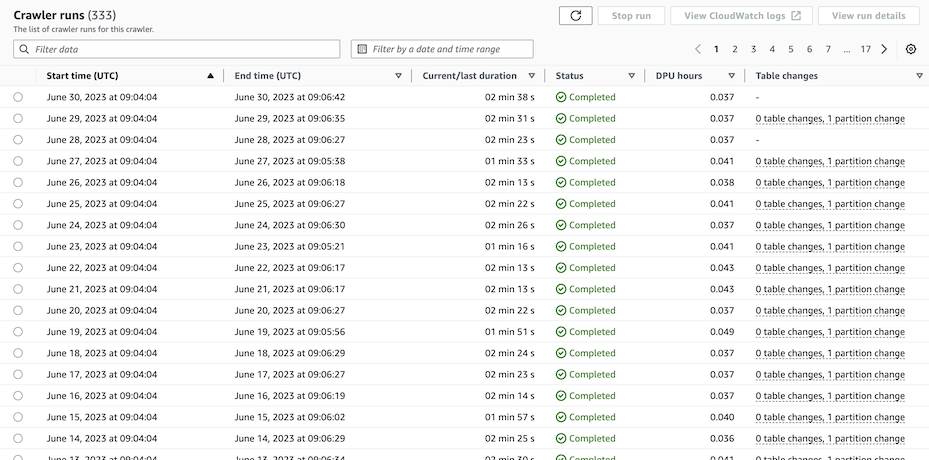
AWS Glue crawler results: after 330 successes, two failures in three days
Succeed the crawlers did, up until this week when some of them failed to find that day’s file, for whatever reason. The screenshot above shows one crawler results’ for the most recent of 333 consecutive days’ execution: the crawler worked for 330 days, then it missed a file (each new file produces one “partition change”), then it found the next day’s file, then it missed a file again. The files were exactly where they should have been, when they should have been there. So there was no raw data missing, I just had to convince the crawler to find the files that it had missed.
This took some doing. Like a lot of complex software systems, you don’t write an imperative program to use the Glue crawler. Instead, you provide lots of information to configure it (see these AWS docs if you are interested.) I ended up adding a custom classifier to each Glue crawler (see these AWS docs), to provide even more information about the structure of the data files. All the files are Comma-Separated Value (CSV) files, and my hope is that my custom classifiers can overcome two problems with the built-in CSV classifier:
This last restriction is despite the fact that the header row is always the very first row in every data file, making it very easy to find. If I could tell the crawler this, it would not even need to go hunting for the header row.
Sadly, the malfunctioning, hard-to-configure Glue crawler isn’t even needed, if AWS provided a way to write a few lines of imperative code to tell the Glue jobs where the new data is located. The new data files are always in the expected, predetermined place, based upon the date, and always have the same header in the same location, the very first row. Alas, there is no way in the standard AWS Glue tooling to do this.
I don’t know what algorithms and heuristics the Glue crawler is applying, and I don’t know why AWS appears to have changed it and made it worse. When you use a powerful tool such as AWS Glue instead of coding everything yourself, you give up some control. My fear is that, as companies apply machine learning to solve more problems, it is going to get harder and harder to understand why the software messed up. Software is losing some of its deterministic nature, and that’s a negative in some situations. Sometimes, a few lines of deterministic code can outperform the most complex algorithms.
Related post: AWS Glue: the good stuff
Related post: AWS Glue: the not-so-good stuff