
|
|
posted: December 17, 2022
tl;dr: Tips and tricks for finding and fixing duplicate database records...
Duplicate records are the bane of databases of reasonable size or complexity. Almost every database I’ve closely examined in my career contains them. The problems they can cause are myriad:
Duplicate records arise for a variety of reasons:
Duplicate records are just one reason why I always look at the data before using a database. Sometimes duplicate records are easy to find, and sometimes they are not.
If the database records contain a unique identifier, either a sequential ID or a UUID, it is very easy to find one major category of duplicate records: if the count of records is greater than the count of unique identifiers, then there are duplicate records. If there is no unique identifier, a timestamp of sufficiently high granularity (down to the millisecond or microsecond) may suffice for finding duplicate records, if the odds of two records having the exact same timestamp is very small.
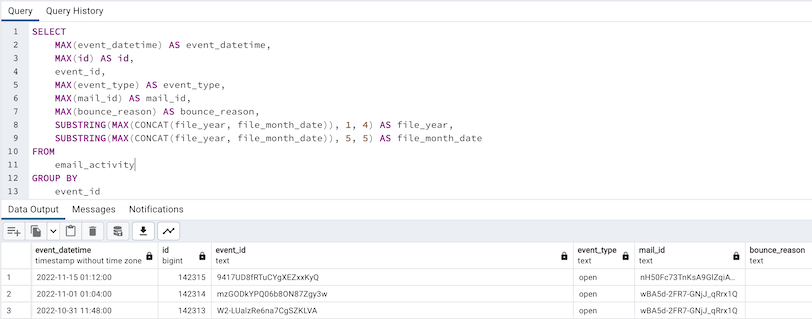
A SQL query to dedupe records in a table where email_id is a unique record identifier
De-duplicating records (deduping) that have a unique ID in a SQL database is a straightforward process. If the desire is to leave the original table intact, perhaps because it is loaded by an ETL job (such as AWS Glue) and should not be altered, one way to do so is to create a SQL view that dedupes the records. Then records can be queried from the view instead of the original table. Or the deduping can be done in every query of the table. One method for deduping is to GROUP BY the unique ID, and then select an aggregation, such as MAX, of every other column in the table, all of whose values should be the same except perhaps for metadata about how or when the records were loaded into the table. The query shown above does so for a table of email_activity records, where event_id is the unique identifier and file_year and file_month_date are metadata about the file that the records came from.
Other types of record duplication can be much harder to find and fix, especially in the case of records for individuals or entities. If the records represent people, you may be able to look for duplicate email addresses, although sometimes different people share the same email address, such as a husband and wife. You can try looking at phone numbers or names, although people may enter their names differently at different points in time, as mentioned in my post on storing database records that lack a unique ID. Machine learning can be used to examine the database and flag potential duplicate records. In the general case it may take some significant human examination to determine if two records that appear to be the same individual or entity are, in fact, duplicates. For this class of problem, the primary remedy is to have humans individually repair the records in the database.
If you are good at deduping database records, you will never lack for work.
Related post: Is your database is missing some records?
Related post: Look at the data
Related post: Play with the data
Related post: Count the data
Related post: Write the bare minimum amount of SQL